PII Sentinel
Presidio plus native PII checks across prompts, responses, and tool calls. GDPR, HIPAA, CCPA evidence pre-mapped.
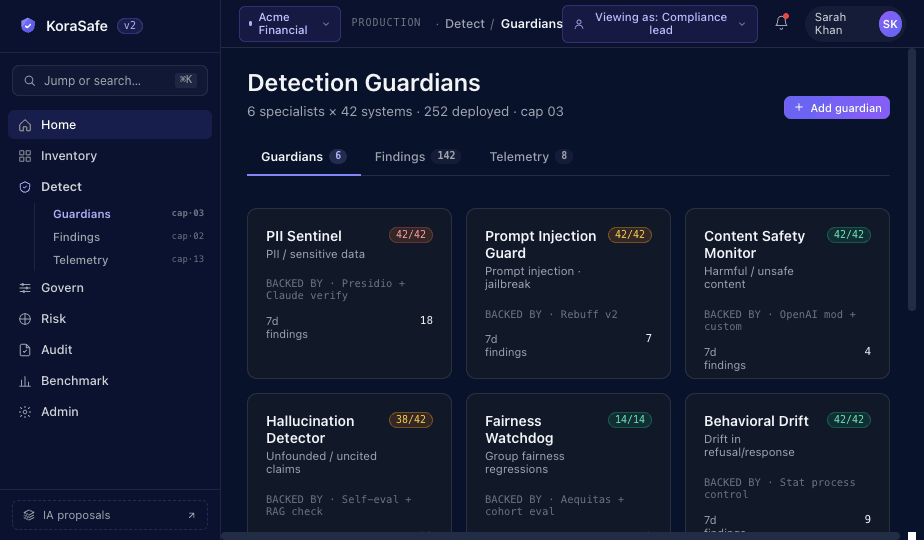
Six detection guardians watch every prompt and response (PII, prompt injection, content safety, hallucination, fairness, behavioral drift). Four agentic guardians evaluate runtime actions before they execute (anomaly, authority, human approval, shadow agent discovery). All ten guardians write findings into the same audit chain your auditor reads from. Federation over replacement: KoraSafe™ normalizes the detectors you already run instead of forcing a swap.
Six detection guardians watch every prompt and response across your AI surfaces. Findings carry the rule that fired, the regulation clause it cites, and route into the same audit chain your auditor reads from.
Presidio plus native PII checks across prompts, responses, and tool calls. GDPR, HIPAA, CCPA evidence pre-mapped.
Heuristic and pattern-based detection for prompt injection attempts. Blocks before the malicious payload reaches the agent.
Native classifiers for moderation across hate, harassment, self-harm, sexual content, and violence categories.
Eval-driven scoring of response groundedness against retrieved context. Flags responses unanchored from source material.
Live-traffic disparity monitoring on protected attributes plus an eval-mode track for labeled sets. Flags decisions where disparate impact crosses configured thresholds.
Watches output distribution shift over time against a baseline window. Flags model behavior moving outside calibrated bounds.
Four agentic guardians evaluate runtime actions before they execute. The SDK calls a checkpoint before an agent spends money, writes data, or contacts a target; the checkpoint returns allow, hold, or block per request. Every decision writes evidence into the audit chain.
Watches agent action frequency, scale, targets, geography, and time-of-day against per-system baselines. Auto-pause is opt-in.
Action-class RBAC before an agent spends, writes, or contacts. SDK gate at /api/action/checkpoint resolves allow / hold / block per request.
Blocks configured action classes until a matching workflow approval is present. Maps to EU AI Act Article 14 oversight evidence.
Discovers AI agents and tools running without registration. Browser, code, identity, and procurement signals feed a triage inbox.
KoraSafe™ does not force a detector swap. The platform normalizes the tools you already run (Presidio, Portkey, LangSmith, MCP-native deployments) into one finding schema, then adds native detection where you have gaps. Evidence lineage, regulatory routing, and coverage reporting layer over what's already in your stack.
Normalize detection feeds from seventeen live partner connectors (Presidio, Portkey, LangSmith, Lakera Guard, Bedrock Guardrails, Datadog, Fiddler, watsonx.governance, Holistic AI, Arize Phoenix, Azure CS, Galileo Luna, Vectara HEM, HiddenLayer, Credo AI, Arize AI, WhyLabs) into one finding schema without changing customer runtime stacks.
Route every finding (from your stack or KoraSafe™'s natives) into the right detection guardian domain. Mapped findings inherit the right regulatory citations automatically.
Pick two frameworks and see which obligations share a control in your environment. Cells color by detection coverage strength. Coverage delta diffs across framework versions, so when the EU AI Act adds an annex you see which obligations gained or lost coverage in your mesh.
Set defaults per guardian and override by system. When a new system registers, the guardians inherit org-level defaults and can be tuned without re-onboarding.
Each guardian below carries the same shape: what it does, what frameworks it provides evidence for, what's live versus roadmap. Click the guardian name to expand.
Catches PII and PHI in prompts, responses, and tool calls. Microsoft Presidio plus native checks back the live detector; redaction policies and framework mapping ship through the same evidence stream as the rest of the platform.
Regulatory evidence for: GDPR Art. 5 / 25 / 32, HIPAA Privacy Rule §164.502(b), CCPA / CPRA §1798.100, EU AI Act Art. 10, ISO 27001 A.5.34.
Honest state: Live in opt-in Preview. Presidio analyzers, native context checks, redaction routing, and framework cross-mapping all run today. Coming next: multilingual entity coverage beyond English, customer-tuned context rules through the admin UI, per-customer detector profile editor.
Heuristic detection runs today in Preview; partner-backed classifier slots are on the roadmap. Customer-flagged patterns feed back into the eval set and grow the heuristic table over time.
Regulatory evidence for: EU AI Act Art. 15, NIST AI RMF MANAGE 4.1, ISO 42001 A.6.2.4, SR 11-7 §IV.
Honest state: Live in opt-in Preview. Inline budget under 50 ms p99. Coming next: partner-backed classifier integration, multilingual coverage, per-tenant rule editor.
Native text classifiers run today in Preview. Severity routing lets customer-support flows route self-harm signals to human help rather than a generic block. Multi-modal coverage and partner-backed slots are on the roadmap.
Regulatory evidence for: EU AI Act Art. 5 (prohibited manipulative content), EU AI Act Art. 50 (transparency for generative output), CFPB UDAAP 12 USC §5531, COPPA 16 CFR Part 312.
Honest state: Live in opt-in Preview (text only). Coming next: multi-modal coverage, multilingual rollout beyond English, partner-backed slot for vendor-attested classifier.
Native RAG-aware grounding ships today in Preview. The detector plugs into existing retrieval steps with no additional retrieval call. Broader factual-claim verification is on the roadmap.
Regulatory evidence for: EU AI Act Art. 13 (transparency), EU AI Act Art. 15 (accuracy + robustness), NIST AI RMF MEASURE 2.7, FCRA 15 USC §1681e(b), SR 11-7 §V.
Honest state: Live in opt-in Preview. Inline budget under 200 ms p99. Source verification against trusted regulatory sources runs today; coming next: broader claim attribution graphs and per-customer source-trust profile.
Live-traffic disparity monitoring runs today without labeled eval sets; severity routes by regulatory regime and writes evidence into the audit chain with NYC LL 144 and EU AI Act Annex IV mappings attached. Eval-mode hooks still ship for teams that maintain labeled eval sets. Partner-backed metric coverage is on the roadmap.
Regulatory evidence for: Civil Rights Act Title VII, ECOA 15 USC §1691, FHA 42 USC §3601, EEOC AI guidance, NYC Local Law 144 §20-870, DOJ ADA AI Hiring guidance, HUD Tenant Screening FHEO guidance, EU AI Act Art. 10.
Honest state: Live-traffic and eval-mode coverage both run today in opt-in Preview. Coming next: partner-backed metric integrations, per-customer protected-attribute editor.
Native statistical detection runs today on a weekly schedule in Preview. Findings carry the prior-period baseline pinned for the human reviewer. Continuous near-real-time scoring and deeper distributional tests are on the roadmap.
Regulatory evidence for: EU AI Act Art. 72 (post-market monitoring), NIST AI RMF MANAGE 4, SR 11-7 §VII, ISO 42001 A.6.2.6.
Honest state: Weekly scheduled scan live in opt-in Preview. Coming next: continuous near-real-time drift scoring, deeper distributional tests (KS, MMD), per-customer baseline calibration UI.
Runtime statistical checkpoint live in opt-in Preview. Outliers above the configured sigma threshold trip a finding; auto-pause is opt-in per system. Default frequency threshold 4σ, scale threshold 10x.
Regulatory evidence for: EU AI Act Art. 14 (human oversight with automated stop conditions), SR 11-7 §VI (effective challenge + automated kill switches).
Honest state: Live in opt-in Preview. Frequency, scale, and target checks all evaluate today. Coming next: per-action-class custom sigma thresholds in the admin UI, baseline carve-outs for seasonal spikes, break-glass workflow integration.
Pairs the runtime checkpoint to an approved task record and an audited reviewer decision. Missing or pending approvals generate a finding in the findings queue; an approved task lets the action through.
Regulatory evidence for: EU AI Act Art. 14 (meaningful human review), GDPR Art. 22 (right to human review of automated decisions), NYC Local Law 144 §20-870, HIPAA Privacy Rule §164.530.
Honest state: Live in opt-in Preview. Policy classes, approval bindings, and audited rejection all run today. Reviewers receive notifications and complete the approval inside the existing workflow surface. Coming next: per-class custom reviewer-routing rules, expiring approvals with auto-revoke, SLA reporting on approval cycle time.
Browser activity, code commits, identity provider events, and procurement records feed a discovery inbox. Analysts review the matched evidence, register the agent into the inventory, dismiss with reason, escalate, or mark experimental. Every transition writes an audit entry.
Regulatory evidence for: EU AI Act Art. 17 (registration of high-risk AI systems), ISO 42001 A.6.2.1 (AI system inventory), NIST AI RMF MAP 4.2.
Honest state: Discovery and inventory triage live in opt-in Preview. All four signal sources flow into the discovery inbox today. Coming next: per-source signal weighting in the admin UI, auto-classification heuristics for high-confidence discoveries, bulk action on triage queues above a configurable size.
All ten guardians are wired into the platform today. Detection guardians (PII Sentinel, Prompt Injection Guard, Content Safety Monitor, Hallucination Detector, Fairness guardian, Behavioral Drift Detector) run at sub-50ms p99 on the fast path with the native classifiers. Agentic guardians (Anomaly Killer, Authority Limiter, Human Approval Gate, Shadow Agent Sentinel) are in opt-in Preview. Your team owns the per-guardian tuning thresholds, the policy decisions on what each guardian blocks vs warns on, and the response workflows when a guardian fires; KoraSafe™ captures the evidence on every decision.
Six detection guardians at sub-50ms inline p99 plus the federation mesh against seventeen production connectors.
Four agentic guardians (anomaly, authority, human approval, shadow discovery) gated for cohort onboarding.
A native classifier rev across the detection set, plus deeper distributional tests for behavioral drift.
Federation over replacement: KoraSafe™ normalizes the detector stack you already run. The Live column lists production connectors with severity scoring and normalization; the Roadmap column names what's committed to ship next.
Connectors move to Live only when the adapter sits in the source tree, the partner API runs under test, and an end-to-end production deployment has cleared the customer-runtime smoke test. Roadmap names commit KoraSafe™ to ship; they do not commit a date.
Source of truth: lib/connectors/ in the platform repo. If your detection stack runs on something not in either column, the federation adapter pattern accepts new connectors without changing the customer runtime.
Same guardian code, different data path. Pick the trust boundary that fits your industry. Most teams start with the sidecar; gateway and embedded SDK exist for the architectural patterns where the sidecar is the wrong shape. For agents you cannot wire to the SDK (vendor SaaS, Microsoft Copilot deployments, browser-based copilots), the fourth access mode is black-box probe testing, which writes the same audit-grade evidence without touching the agent runtime.
A pod that runs next to your application in Kubernetes. Your agent code calls the local sidecar over loopback; the sidecar evaluates all ten guardians and writes findings to the audit chain. No agent code change beyond the LLM client wrapper. Familiar pattern for any team that already runs Envoy, Linkerd, or Istio. Scales horizontally with your application.
Pick this when: you run on Kubernetes, you want zero changes to existing agent logic, and you want guardian rollout decoupled from agent deploys.
A central proxy that fronts your LLM provider URLs. Every request to OpenAI, Anthropic, Bedrock, or a self-hosted model goes through the gateway first; guardians evaluate prompts on the way in and responses on the way out. One audit point for every agent across every team, no per-agent install. Requires you to reroute your LLM base URL from api.openai.com to the gateway endpoint.
Pick this when: you run on bare metal or non-K8s infrastructure, you want a single chokepoint for governance, or you have many small agents and centralized auditing matters more than per-pod isolation.
A library you import directly into your agent process. Guardians run in-process on the same thread as your inference call. Sub-10ms inline overhead because there's no network hop. The trade-off is coupling: guardian updates ship as library version bumps, and a runaway guardian can affect your agent's memory and CPU footprint.
Pick this when: you serve hyper-latency-sensitive workloads (real-time agent loops, voice, trading), you control the agent runtime end to end, and the operational coupling is acceptable.
All three deployment shapes ship in two data postures. Pick the trust boundary; the guardian code is identical either way.
Findings, evidence, and audit records persist in KoraSafe™-managed cloud infrastructure. Simpler setup, faster onboarding, no infrastructure to operate. Per-tenant isolation enforced at the data layer. Suits most teams in non-regulated and lightly regulated industries.
Findings, evidence, and audit records persist in customer-owned storage (your S3, Azure Blob, GCS, or on-prem MinIO). Only metadata telemetry crosses the trust boundary to KoraSafe™; raw content stays in your network. Suits regulated industries (financial services, healthcare, public sector) and any team whose policy prohibits prompt or response content leaving the perimeter.
Deeper detail (install commands, network diagrams, latency budgets, failure modes) lives in docs/deployment/topology.md. Air-gap mode for SCIF and classified-network environments is documented separately in docs/deployment/air-gap.md. For third-party agents that cannot land in either data posture (vendor SaaS chatbots, Copilot fleets), see black-box probe testing.
Kora agents watching every system for PII, prompt injection, hallucination, fairness drift, and behavioral profile change.
Start your free trial for onboarding. All ten guardians configurable from the guardian portal, all writing into the same audit chain.