Weighted, attributable components
Every score names the six factors and their weights. Your team sees exactly which factor moved when a score changes; auditors get the inputs and the math.
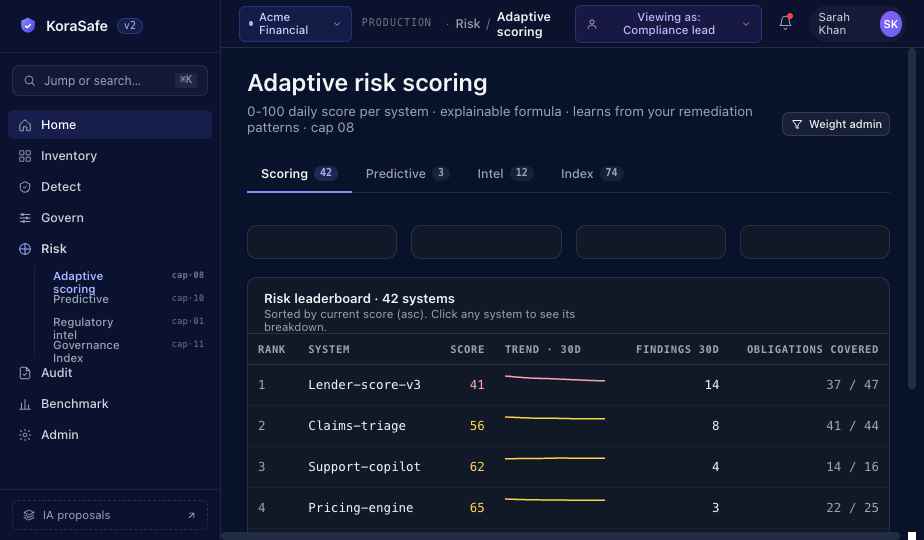
Adaptive risk scores every AI system in your registry on a 0-100 scale with named, attributable components. New systems run through a pre-launch gate before the first request. Peer benchmarking shows where your governance posture sits in your sector cohort, with k-anonymity preventing peer identification.
A six-factor composite (regulatory exposure, autonomy tier, data sensitivity, blast radius, eval coverage, finding density). Factor weights adjust to your org's actual finding patterns within bounded learning so the weights don't drift. Quarterly methodology snapshots pin the formula version that produced each score, so regulators can verify which methodology was in use when a score was generated.
Every score names the six factors and their weights. Your team sees exactly which factor moved when a score changes; auditors get the inputs and the math.
Risk shifts when the applicable law changes. A system newly in scope for the EU AI Act gets re-scored against the relevant articles automatically; your team doesn't reset weights manually.
Sort and filter systems by what needs action first. Risk leaderboard surfaces the highest-risk systems with their decomposed component contributions inline.
For systems that need a quantitative loss-magnitude framing, the score breakdown surfaces Factor Analysis of Information Risk decomposition. Loss event frequency and loss magnitude factors render with low / mode / high values and confidence per factor. Full rubric on the FAIR risk methodology page.
Most governance tools catch problems after a system ships. The pre-launch gate evaluates a written intake (purpose, data classes, autonomy tier, deployment regions) against versioned rule packs before the first request. Verdict: pass, block, or conditional with a remediation path.
Versioned per-sector rule packs evaluate purpose, data class, autonomy tier, and jurisdiction. Updates to a pack re-evaluate registered systems automatically.
Rules apply based on declared deployment regions. A system scoped to Colorado gets Colorado AI Act checks; one scoped to Ireland gets EU AI Act Article 14.
Pass, block, or conditional with a check-by-check breakdown. Conditional verdicts list the controls that must be in place before launch; blocked systems get a remediation path, not just a hard stop.
Runs as a GitHub Action on every PR or new system registration. Teams get a verdict before code merges, not after an audit cycle.
Backend cohort collection and k-anonymity safeguards run on the platform. Compare your org against anonymized sector cohorts on four governance metrics: governance index, control coverage, remediation close rate, and shadow AI ratio. Charts stay hidden until a cohort clears five distinct opted-in orgs; aggregate distributions only, never raw peer rows.
Cohorts split by sector, size band, and region. Buckets stay stable across opt-in cycles, so flipping subscription does not reshuffle peers.
Charts stay hidden until a cohort clears five distinct opted-in orgs. Below threshold, metrics show as withheld; no inferred values render.
Benchmark narratives explain what good looks like for the cohort without exposing peer identities. For boards that ask "are we ahead of our peers."
Aggregate distributions only. Cohort responses return medians and quartiles, never raw customer or peer rows. Full privacy model on the peer benchmarking methodology page.
Decomposed risk scoring is live with per-org weight learning. The pre-launch gate runs against versioned rule packs and integrates as a GitHub Action. Peer benchmarking backend cohort collection and k-anonymity safeguards are live; live peer-cohort signal unlocks as more orgs in each sector and size band opt in (five-org minimum per cohort). Your team still owns the framework subscriptions (which laws apply to which systems) and the remediation decisions when a score moves; KoraSafe™ captures the math and the evidence behind every number.
Decomposed risk score + per-org weight learning + FAIR
Pre-launch gate as GitHub Action + intake form + verdict card
Adaptive risk scoring per AI system, with predictive forecasting and the per-factor breakdown your audit committee will ask for.
Request a guided walkthrough. Adaptive risk, pre-launch gate, peer benchmarking in one platform.